
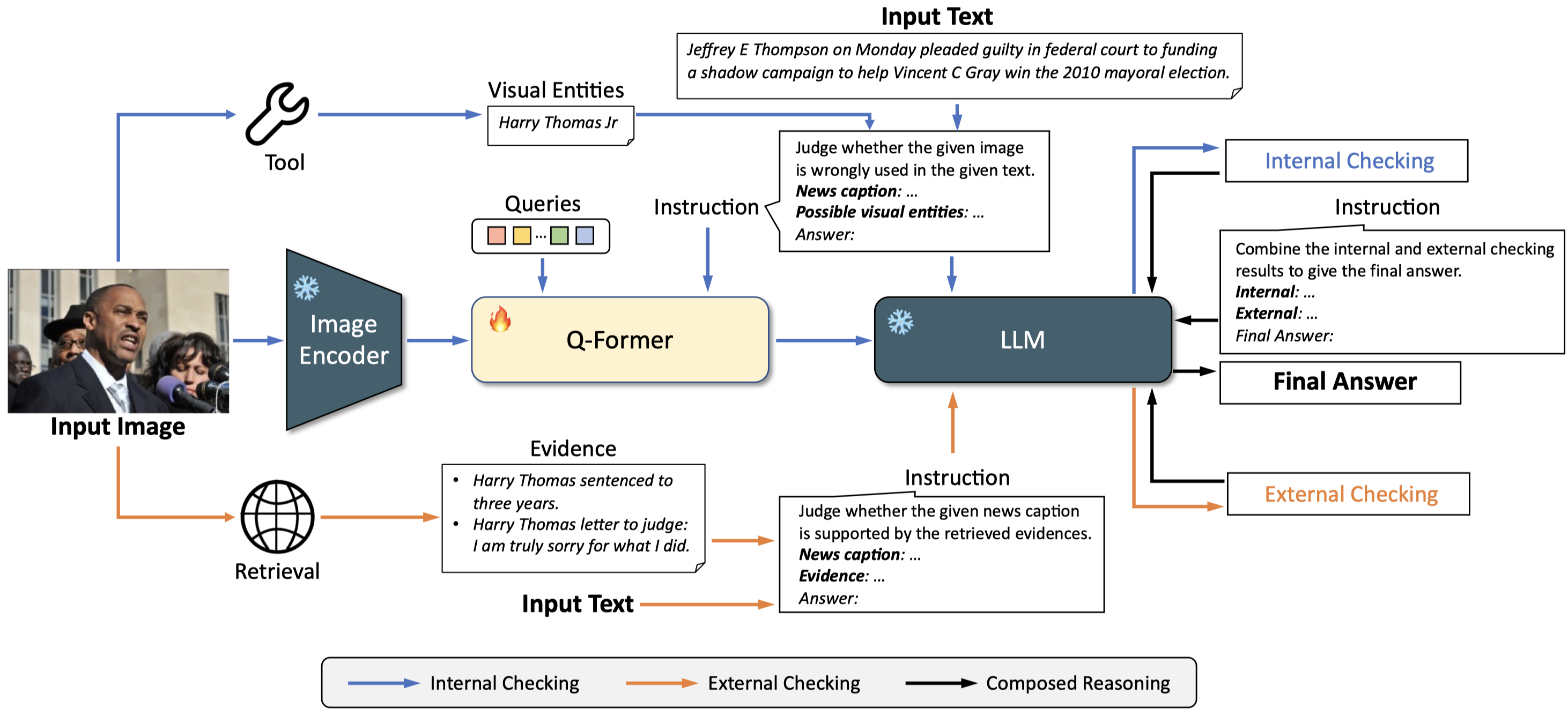

Instruction Tuning Process
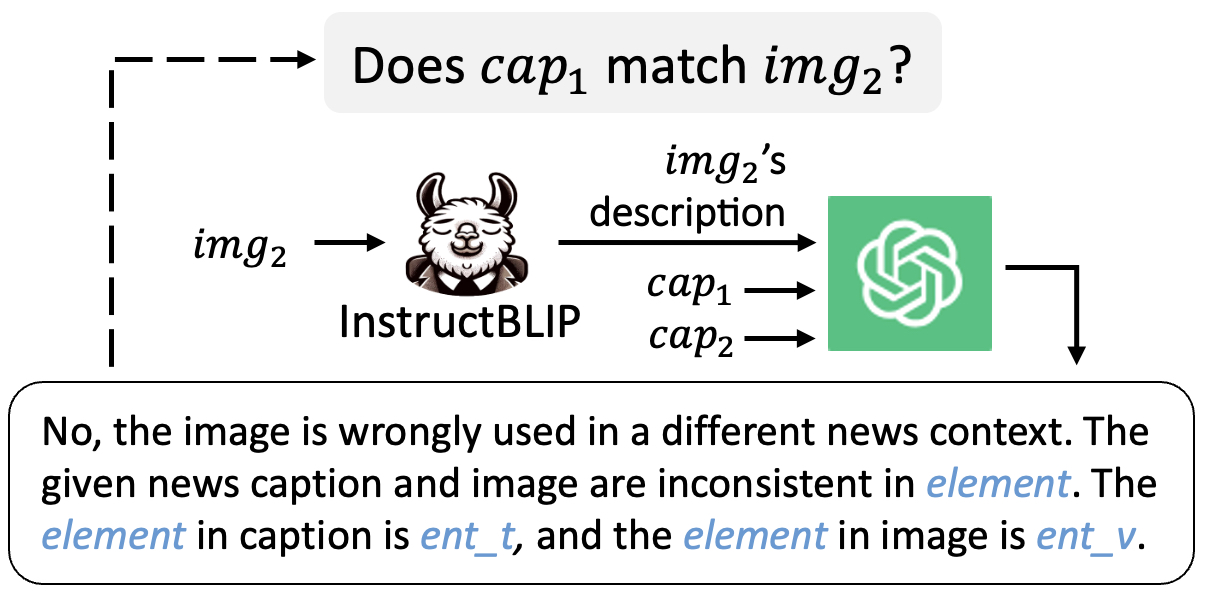
Task-Specific Instruction Construction
(with judgment and explanation)
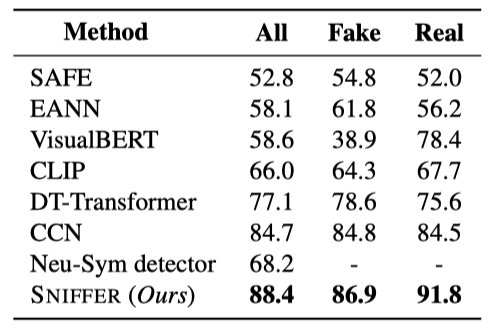
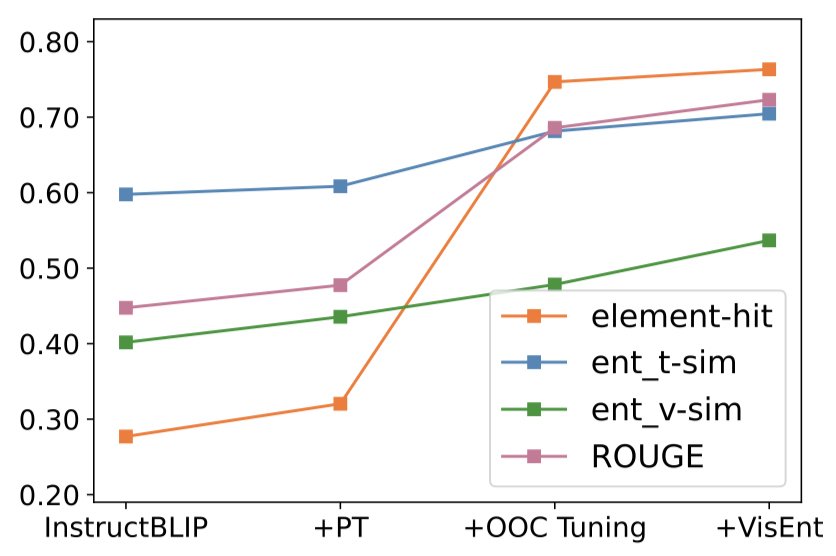
@InProceedings{Qi_2024_CVPR,
author = {Qi, Peng and Yan, Zehong and Hsu, Wynne and Lee, Mong Li},
title = {SNIFFER: Multimodal Large Language Model for Explainable Out-of-Context Misinformation Detection},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {13052-13062}
}